5.2 Text
How can neural networks process texts, or: What are language models?
Neural networks process numbers and produce numbers. But how can they classify, compare, recognise, translate, and generate texts? The solution is obvious: texts must also be converted into numbers.
The most straightforward idea might be to simply encode letters as numbers (A=1, B=2, C=3, and so on). Unfortunately, this does not work. Technically, it’s possible, but the result would not make sense. The neural network would not truly understand the structure of our language, but only learn the association that A corresponds to the value 1, B to 2, and so forth. This is why we use a super-effective and surprisingly simple trick called embedding, which will now be explained in more detail.
Neural networks learn from data. This also applies to texts, which can be directly used to create a language model. The example that will be discussed here was developed with German vocabulary, with the verbatim English translation provided for reference. Let's look at the following twelve sentences from which we want to create our mini language model. All German sentences consist of only 20 words in total:
- Der Junge spielt Fußball auf dem Rasen [The boy is playing football on the pitch]
- Der grüne Rasen ist schön [The green pitch is beautiful]
- Der Fußball rollt auf dem Rasen [The football is rolling on the pitch]
- Auf dem Rasen spielt der Junge [On the pitch, the boy is playing]
- Der Junge rollt den Fußball [The boy is rolling the football]
- Auf dem Rasen rollt der Fußball [On the pitch, the football is rolling]
- Schwarze Raben landen auf dem Rasen [Black ravens are landing on the pitch]
- Raben fliegen über dem Rasen [Ravens are flying over the pitch]
- Auf dem Fußball landen schwarze Raben [On the football, black ravens are landing]
- Der Junge sieht schwarze Raben am Himmel fliegen [The boy sees black ravens flying in the sky]
- Am Himmel fliegen Raben [In the sky, ravens are flying]
- Der Himmel ist schön [The sky is beautiful]
From the twelve sentences, 200 training data-items can be generated immediately if a vocabulary word is consistently trained alongside its neighbours. To do this, pairs are formed continuously: one vocabulary word as input x and a neighbouring vocabulary word as the desired output y. At first this approach might not seem very plausible, but it does ensure that words frequently found together are given similar weights inside the network, which will be useful later on. Let's take a look at an example sentence and observe how nine training data pairs are created from the first three words of the sentence. The pairs are formed in such a way that a word (highlighted in yellow) is ideally combined with all four neighbouring words that surround it. When the word appears at the beginning of a sentence, this results in correspondingly fewer pairs.
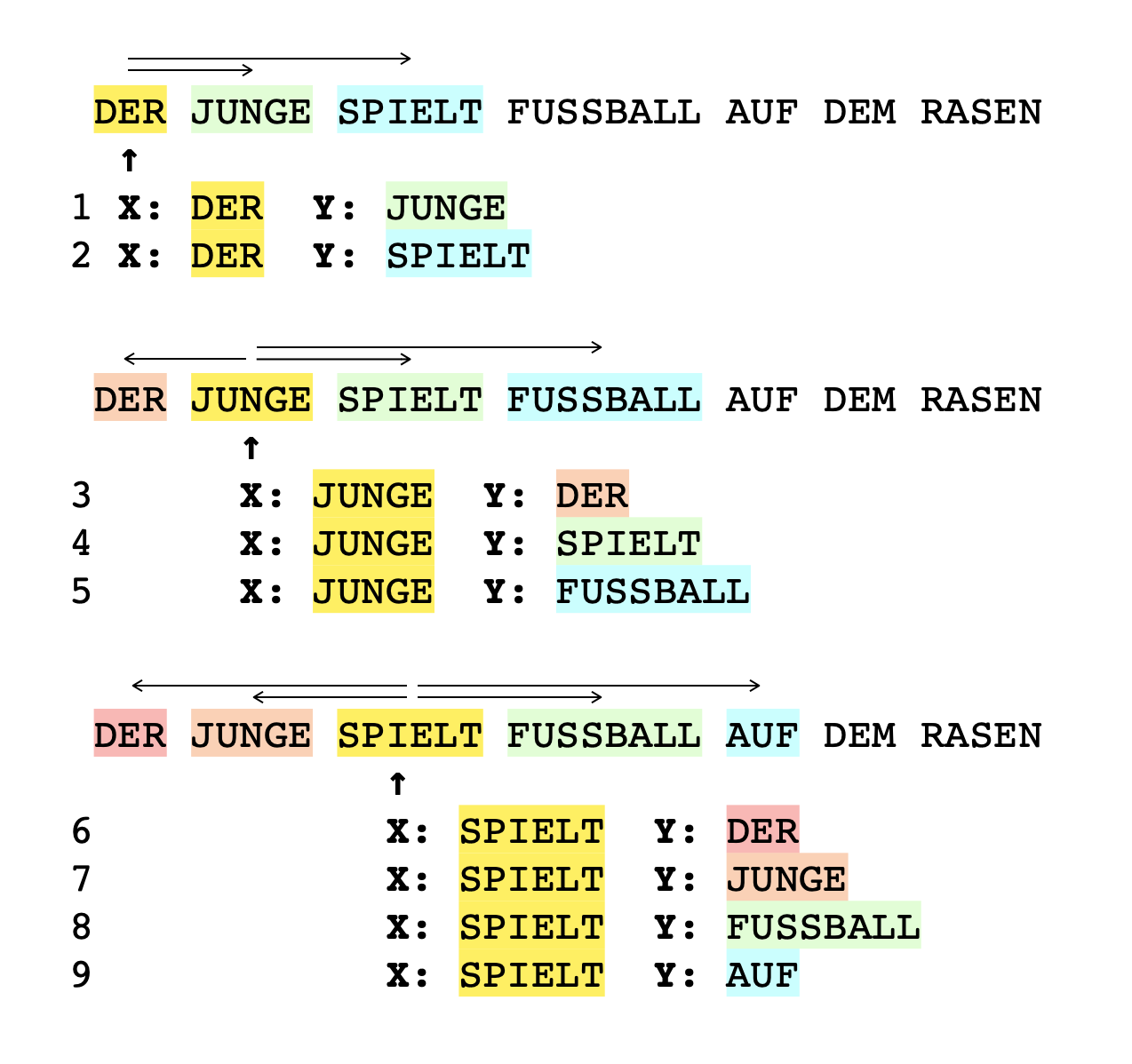
In order to prepare the vocabulary for further processing with a neural network used for the actual embedding, each vocabulary word is converted into a number. This number has the same number of digits as there are vocabulary words. The trick here is to represent each word as a different input (and output) with 20 digits, where all digits are 0 except for one (we have already learnt about this as One Hot Encoding):
- "DER" is the first word appearing in the text and is encoded as 10000000000000000000
- "JUNGE" is the second word and becomes 01000000000000000000
- "SPIELT" is assigned the value 00100000000000000000
- ... until the last word "HIMMEL" (sky), which is encoded as 00000000000000000001.
Using this procedure, the above text results in a total of 200 pairs of training data:
A neural network is then used for the actual embedding, e.g. a 20-2-20 neural network as shown below. Since there are 20 different vocabulary words, the neural network has 20 inputs and 20 output neurons. Each neuron in the input and output layer can therefore be assigned a fixed vocabulary word (written as a 20-digit number with a 1 at the position of this neuron). In the middle layer, the number of neurons is selected as the size to which a vocabulary word is to be compressed. As the middle layer contains two neurons in this case, exactly two weights are trained per vocabulary word, representing the vocabulary word converted into numbers. These two numbers are the embedded form.
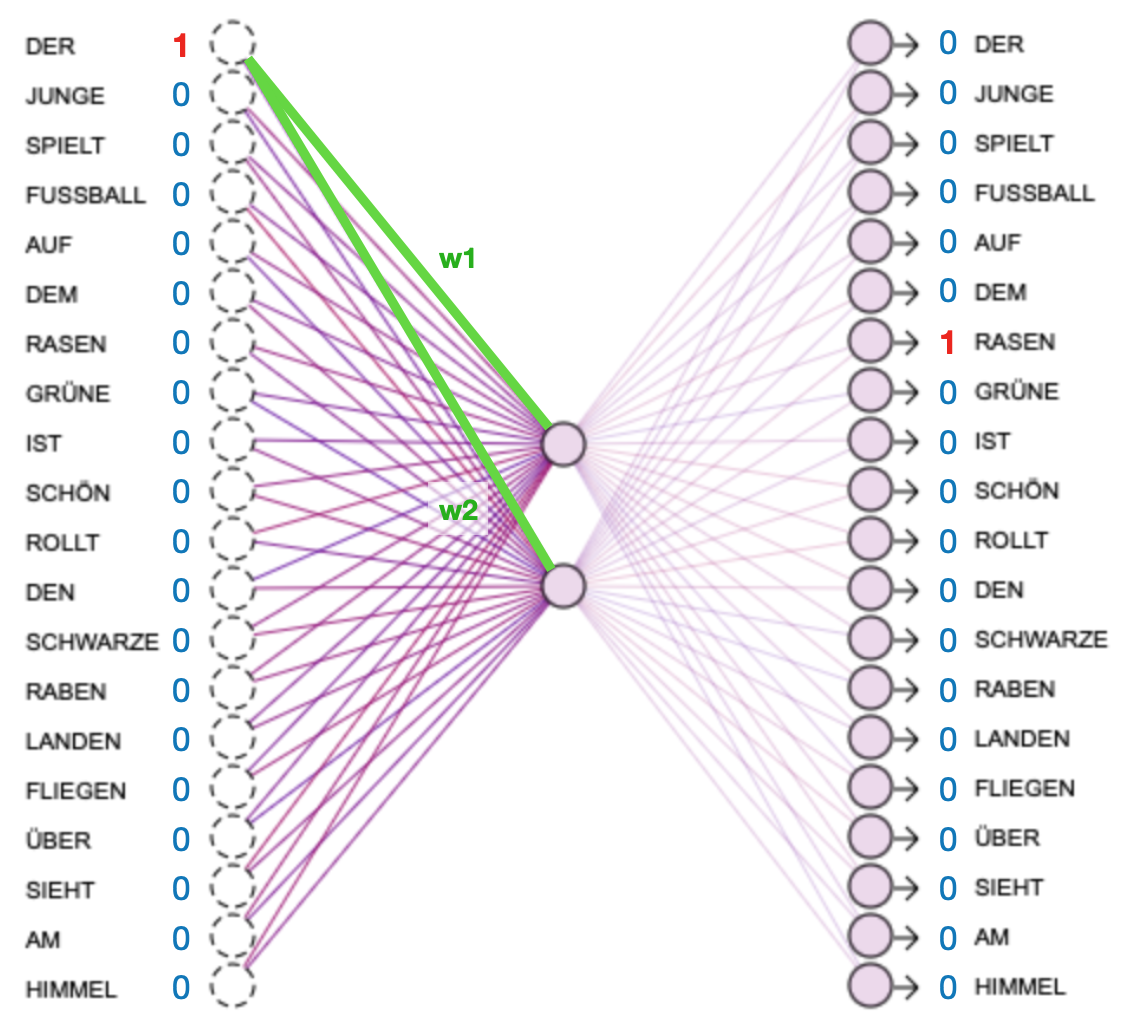
Representation of the training pair x:DER (the) / y:RASEN (pitch)
Since the two weights w1 and w2 are trained for each vocabulary word, these can then be used as the embedded encoding of the word. In the interactive illustration below, they are represented as x- and y-coordinates to visualise the similarity of the vocabulary words that the neural network has learnt from the training data.
Instructions
- Click
Train: The network is trained with the vocabulary pairs shown above until it can match them sufficiently well. At the same time, the similarities between the vocabulary words are displayed on the right-hand side of the figure. Each vocabulary word is represented by two numerical values (w1 and w2), which are used as x- and y-coordinates. The closer two words are, the more similar they are in terms of content. - Click
Stop: The training process is interrupted. To resume training, clickTrain. - Click
Reset: Everything that the network has learnt is reset, and new random values are chosen for all weights. - Click on the vocabulary words in the left part of the figure. Their values in the embedded space and their position in the right part of the image will be displayed.
The model in application
In the following, four partially new sentences will be compared in pairs. One might assume that the first two sentences are most similar to each other, as they are identical except for one letter. However, once the network has been trained, the sentences are grouped not by external similarity, but by internal meaning. In fact, the first and last sentences (possibly also the second and third sentences) should have the greatest content similarity, because the neural network can now make the (meaningful) connection that ravens are in the sky and the football is on the pitch.
1. Der Junge sieht Raben [The boy sees ravens]
2. Der Junge sieht Rasen [The boys sees a pitch]
3. Der Junge sieht Fußball [The boy sees a football]
4. Der Himmel ist schön [The sky is beautiful]
To do this, the x and y coordinates of the encoded words are added together, and the so-called cosine similarity between the two sentences is then determined. This involves a very simple mathematical calculation of the angle between the numbers. The following table shows how similar the sentences are to each other in terms of content. This is done on a scale from -1 (opposite) to 1 (very similar).
| Sentence 1 | Sentence 2 | Result |
| Der Junge sieht Raben | Der Junge sieht Rasen | |
| Der Junge sieht Raben | Der Junge sieht Fussball | |
| Der Junge sieht Raben | Der Himmel ist schön | |
| Der Junge sieht Rasen | Der Junge sieht Fussball | |
| Der Junge sieht Rasen | Der Himmel ist schön | |
| Der Junge sieht Fussball | Der Himmel ist schön |
The embedded form of a word can now be optimally used for further processing with neural networks, as it consists only of numbers, and these numbers also reflect the similarity to those words that are similar in content. Such embedding is the first important step for neural networks that process natural language. It is not uncommon to use networks with over 10,000 vocabulary words (and input and output neurons). Instead of relying on just two values as in the example above, the vocabulary is mapped to a few hundred numbers for further processing.
Share this page
