5.1 General
At this point, let's look back at the introductory example: the prediction of who would and who would not survive the sinking of the Titanic. This is a typical example of classification, which will be used to explore the following points:
Data preparation
Good data preparation is one of the most important tasks when working with artificial neural networks. Ultimately, the aim is to convert information into numbers so that it can be processed, and information will in turn be obtained at the end of a classification. However, this process can unintentionally introduce errors. In the initial example, for example, we needed to encode gender. Therefore, 1 was selected for male and 0 for female. While the ticket categories (1st to 3rd class) are easy to convert into numbers (0, 1, 2), they are not well suited for further processing as the numbers are much larger than the numbers representing gender. There are situations in which different value ranges could have a negative influence on correct performance. For example, if the weight (3–200 kg) and the height of a person (0.5–2.5 m) were both used as input values, the weight’s much larger range could disproportionally influence the classification. For this reason, the ticket categories 0, 1, 2 are (internally and invisibly) converted into the numbers 0.0, 0.5 and 1.0 before further processing. Similarly, the departure ports must be converted into numbers. In order to bring the three ports into the value range of 0 to 1, they are also (internally and invisibly) encoded as 0.0, 0.5 and 1.0 based on the order of departures. The number of children, for instance, is displayed in ascending order from 0 to 9 and converted internally into the numbers 0.0, 0.1, 0.2 etc.
Data set size
Most of the examples given on these pages use very small, manageable data sets because the primary focus is on mini-demonstration scenarios. However, when data sets are small and there are hardly more data points than neurons, neural networks may simply memorise the data. Real data sets should therefore contain orders of magnitude more data than neurons.
For instance, the introductory example uses a neural network with 14 neurons and a total of 118 trainable weights and thresholds. However, the training data contains 1300 x 8 = 10400 numbers which the neural network learns from. This ratio indicates with reasonable certainty that the network has not simply memorised all the data at the end of the training but can generalise well (i.e. it extracted meaningful trends from the data).
Difference to algorithms
When learning a programming language, you learn that you yourself are responsible for the quality of an algorithm when programming. If, for example, you want to program a function f that returns output y for an input x, you must precisely define how the output is calculated from the input and ensure that it is always identical.
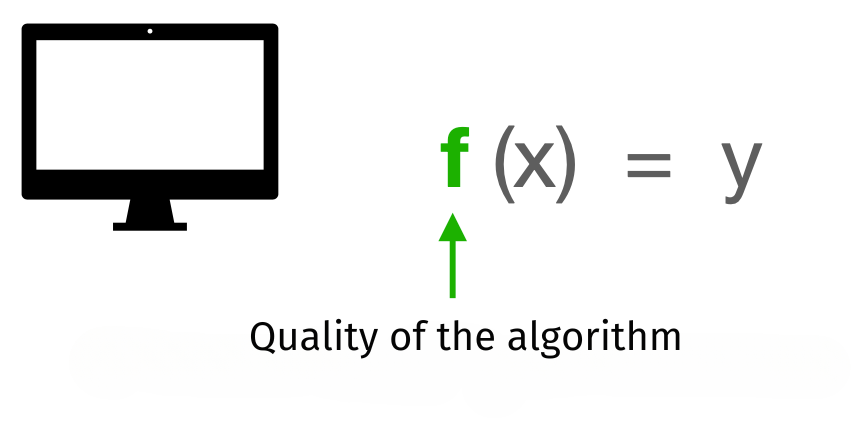
This is different for neural networks. To continue with the example above, the untrained neural network is initially provided as a “quasi-empty” function f. The network gains knowledge about how to derive output y from input x solely through training with the combination pairs of input data (x) and output data (y). The network’s function is constructed only from the data, with the relationship between x and y increasingly stored in the network’s weights and thresholds. Therefore, the quality of the data used determines the quality of the network in a decisive way.

Training, validation and testing
When we started out, the introductory example was described as using a training data set consisting of 1300 rows with 8 values each. More precisely, the data set was actually divided into two parts. Out of the 1300 patterns, 900 patterns were selected to train the network, while the remaining 400 patterns were not used for training at all. Instead, these 400 patterns were used to test the network after training. Since we know which class (survived, not survived) each pattern of the test data belongs to, we can now send each individual pattern through the neural network and check whether the desired output of the network matches the actual output (or not). The percentage of correct matches (which was 321 out of 400) corresponds exactly to the 80 per cent of data that the neural network accurately predicts – even though it has never seen the test data before. This approach ensures that the neural network did not merely memorise the training data.
Often, a second test data set is used, the so-called validation set. For this purpose, the total data set is split, for example, in a 60:20:20 ratio. During training, the validation data set is used to regularly assess how well the network handles unknown data. If the recognition rate of the unknown data decreases after being clearly better before, you should stop in time so that the neural network does not start memorising the training data, which is known as overfitting. In addition to this, there are numerous other tactics to prevent neural networks from being trained incorrectly.
Classification
The purpose of the neural network in the introductory example was to use data to make a statement as to which of the two groups (classes) the input data falls into (survived/not survived). Such a prediction (e.g. healthy/sick, young/old), but also a prediction such as elephant, zebra, house, bicycle in the field of image recognition is called classification. Typically, one selects one output neuron per class that should deliver 1 as the desired output. When there are only a few classes, a single output neuron may be enough, with its output representing the class (e.g. 0 = survived, 1 = not survived). However, when feeding neural networks with data such as stock prices in view of making predictions for the future, it is not classification, as the aim in this case is not to recognise group membership, but to predict how the curve will continue. This is known as regression[1].
Bias
No matter how much effort is put into the design of a neural network, problems and serious misbehaviour of the network can still occur. There are even blogs on the internet that collect curious stories about failed neural networks or AI systems. Often, errors in the data set are responsible for neural networks not functioning as they should – since, as mentioned above, the quality of a network largely depends on the quality of the data set it is trained on. Problems in the data are somewhat confusingly referred to as bias (a term also used to designate the threshold value).
When certain groups are overrepresented or underrepresented in the data set, this can lead to biases. Data can reflect cultural prejudices: historical inequalities or stereotypes, for example, may result in certain population groups being disadvantaged or underrepresented in the data. Moreover, certain characteristics or aspects may not have been recorded correctly due to errors during data collection. It is essential to avoid these and other forms of biases in the data set.
Interpretation
An artificial neural network is a mathematical-statistical program. It is not a brain and cannot think or plan. It also has no intentions and cannot autonomously learn something entirely new or different. The neural network only learns from the available data during training. Afterwards, it can be used to classify test data or new data, for example. Comparing it to the human brain is like comparing a paper airplane to a [2]: both can fly and have similar design principles, but the differences are striking. In many situations, it even makes more sense to use a well-designed algorithm rather than a neural network – despite the increasing popularity of neural networks.
Graphically, “regression” usually refers to extrapolating a line backwards – here we are extrapolating forward.
https://divis.io/en/2020/06/most-common-mistakes-about-neural-networks/
Share this page

