5.6 Image generation
On the previous page, we learnt about the structure of an autoencoder. Autoencoders are used in various applications, including in the field of image processing. For instance, they can be used to reduce noise in images by compressing the image, removing the noise, and then reconstructing it. They can also be used (usually in a slightly modified form) for image generation, which will be shown in a simplified form here.
In the following, an autoencoder is presented that was trained with several hundred images of apples and bananas, each measuring 16x16 pixels and containing colour channels for red, green, and blue). The pixel values of the images were used as input, resulting in a total of 768 inputs (16x16 pixels x 3 colours). As is common with autoencoders, the neural network was designed to learn to produce the exact same image as output for each input. For this purpose, the network architecture consisted of a total of 768+256+16+4+16+256+768 neurons (illustrated schematically in the following figure).
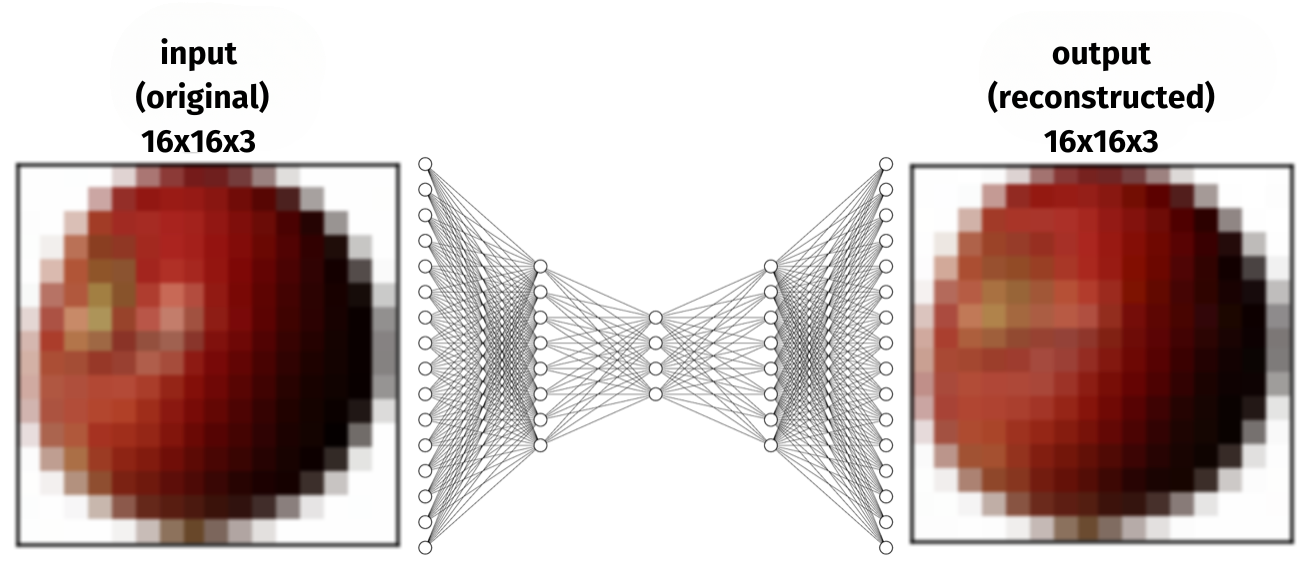
Interestingly, after training, you can remove the encoder (i.e. the left part) and only use the decoder, which is what happens below. Since each image is reduced to four neurons and thus to four numerical values (which is actually enough to reconstruct the input image reasonably well), the decoder can now be used to generate images. This is done by using the four neurons as inputs and changing their values. It is now even possible to generate images that were not exactly part of the training data, such as images of an exotic “banapple”.
Instructions
- Use the four sliders to change the input values of the decoder to values between 0 and 1. The image generated from the four values is calculated and displayed directly.
- Note: The original data set showed the same apple or banana from many different perspectives.
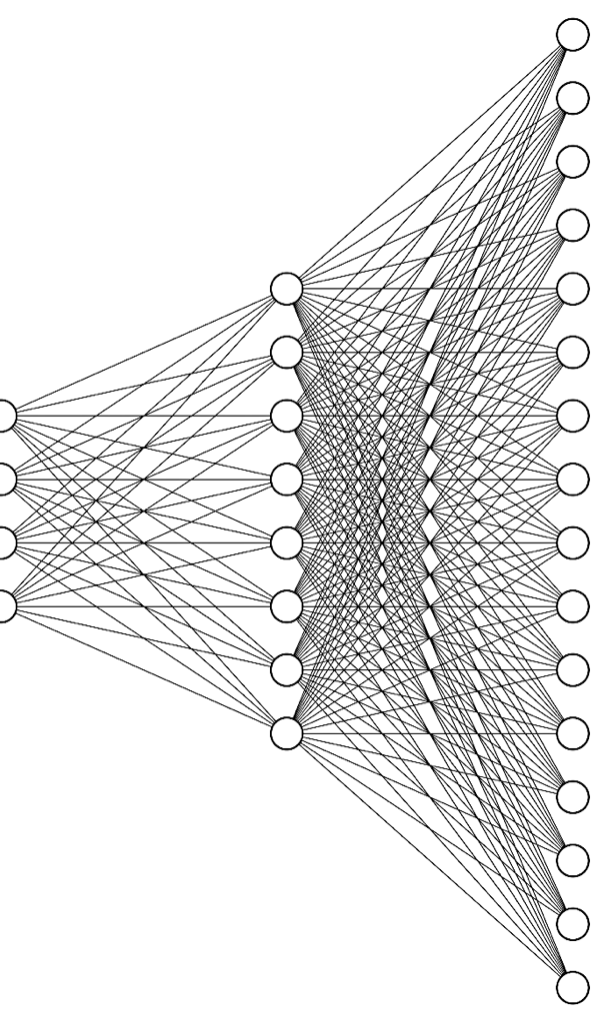
Tasks
- Try to generate an apple, a banana, and a “banapple”.
- Try adjusting the sliders to create strange images that were likely not present in the training data set.
The following shows a few extracts from the training data of the original autoencoder together with the result, i.e. the reconstruction of the input. The training length was several hundred thousand training steps until a halfway acceptable reconstruction was achieved. Although each image was compressed into only four numerical values, the reconstruction is almost perfect. Note that this is a simplified variant of image generation. Using e.g. convolutional neural networks will improve the quality and the possibilities enormously.

Training data from Horea Mureşan, Acta Univ. Sapientiae, Informatica Vol. 10, Issue 1, pp. 26-42, 2018.
Data set: https://github.com/Horea94/Fruit-Images-Dataset/blob/master/LICENSE
Share this page
